
Analysis of Multi-Threading and Cache Memory Latency Masking on Processor Performance Using Thread Synchronization Technique
DOI:
https://doi.org/10.14295/bjs.v3i1.458Keywords:
concurrency, multithreading, mutex, semaphore, synchronizationAbstract
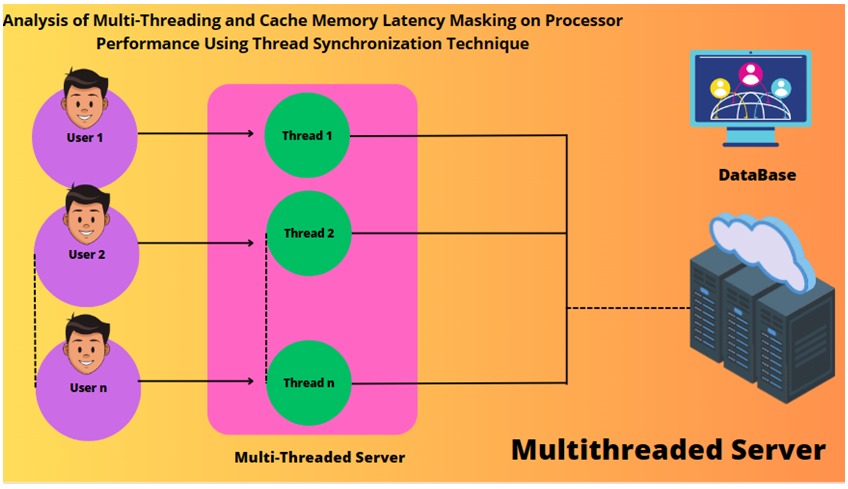
Multithreading is a process in which a single processor executes multiple threads concurrently. This enables the processor to divide tasks into separate threads and run them simultaneously, thereby increasing the utilization of available system resources and enhancing performance. When multiple threads share an object and one or more of them modify it, unpredictable outcomes may occur. Threads that exhibit poor locality of memory reference, such as database applications, often experience delays while waiting for a response from the memory hierarchy. This observation suggests how to better manage pipeline contention. To assess the impact of memory latency on processor performance, a dual-core MT machine with four thread contexts per core is utilized. These specific benchmarks are chosen to allow the workload to include programs with both favorable and unfavorable cache locality. To eliminate the issue of wasting the wake-up signals, this work proposes an approach that involves storing all the wake-up calls. It asserts the wake-up calls to the consumer and the producer can store the wake-up call in a variable. An assigned value in working system (or kernel) storage that each process can check is a semaphore. Semaphore is a variable that reads, and update operations automatically in bit mode. It cannot be actualized in client mode since a race condition may persistently develop when two or more processors endeavor to induce to the variable at the same time.
This study includes code to measure the time taken to execute both functions and plot the graph. It should be noted that sending multiple requests to a website simultaneously could trigger a flag, ultimately blocking access to the data. This necessitates some computation on the collected statistics. The execution time is reduced to one third when using threads compared to executing the functions sequentially. This exemplifies the power of multithreading.
References
Abellán, J. L., Fernández, J., & Acacio, M. E. (2015). Efficient Hardware-Supported Synchronization Mechanisms for Manycores. Handbook on Data Centers, 753-803. https://doi.org/10.1007/978-1-4939-2092-1_26 DOI: https://doi.org/10.1007/978-1-4939-2092-1_26
Adam, G. K. (2022). Co-Design of Multicore Hardware and Multithreaded Software for Thread Performance Assessment on an FPGA. Computers, 11(5), 76. https://doi.org/10.3390/computers11050076 DOI: https://doi.org/10.3390/computers11050076
Almutairi, S. Z., Mohamed, E. A., & El-Sousy, F. F. (2023). A Novel Adaptive Manta-Ray Foraging Optimization for Stochastic ORPD Considering Uncertainties of Wind Power and Load Demand. Mathematics, 11(11), 2591. https://doi.org/10.3390/math11112591 DOI: https://doi.org/10.3390/math11112591
Cai, C., Wang, L., & Ying, S. (2022). Symmetric diffeomorphic image registration with multi-label segmentation masks. Mathematics, 10(11), 1946. https://doi.org/10.3390/math10111946 DOI: https://doi.org/10.3390/math10111946
Candelario, G., Cordero, A., Torregrosa, J. R., & Vassileva, M. P. (2023). Solving Nonlinear Transcendental Equations by Iterative Methods with Conformable Derivatives: A General Approach. Mathematics, 11(11), 2568. https://doi.org/10.3390/math11112568 DOI: https://doi.org/10.3390/math11112568
Carvalho, T., Pinto, J. B., & Cardoso, J. M. P. (2023). A DSL-based runtime adaptivity framework for Java. SoftwareX, 23, 101496. https://doi.org/10.1016/j.softx.2023.101496 DOI: https://doi.org/10.1016/j.softx.2023.101496
Cheikh, A., Sordillo, S., Mastrandrea, A., Menichelli, F., & Olivieri, M. (2020). Efficient mathematical accelerator design coupled with an interleaved multi-threading RISC-V microprocessor. In: Applications in Electronics Pervading Industry, Environment and Society: APPLEPIES 2019 7 (pp. 529-539). Springer International Publishing. https://doi.org/10.1007/978-3-030-37277-4_62 DOI: https://doi.org/10.1007/978-3-030-37277-4_62
Chen, X., Diaz-Pinto, A., Ravikumar, N., & Frangi, A. F. (2021). Deep learning in medical image registration. Progress in Biomedical Engineering, 3(1), 012003. https://doi.org/10.1088/2516-1091/abd37c DOI: https://doi.org/10.1088/2516-1091/abd37c
Dai, A., Zhou, H., Tian, Y., Zhang, Y., & Lu, T. (2020). Image registration algorithm based on manifold regularization with thin-plate spline model. In Neural Computing for Advanced Applications: First International Conference, NCAA 2020, Shenzhen, China, July 3–5, 2020, Proceedings 1 (pp. 320-331). Springer Singapore. DOI: https://doi.org/10.1007/978-981-15-7670-6_27
Eslamimehr, M., Lesani, M., & Edwards, G. (2018). Efficient detection and validation of atomicity violations in concurrent programs. Journal of Systems and Software, 137, 618-635. https://doi.org/10.1016/j.jss.2017.06.001 DOI: https://doi.org/10.1016/j.jss.2017.06.001
Fu, Z., Chu, S. C., Watada, J., Hu, C. C., & Pan, J. S. (2022). Software and hardware co-design and implementation of intelligent optimization algorithms. Applied Soft Computing, 129, 109639. https://doi.org/10.1016/j.asoc.2020.109639 DOI: https://doi.org/10.1016/j.asoc.2022.109639
Hassanein, A., El-Abd, M., Damaj, I., & Rehman, H. U. (2020). Parallel hardware implementation of the brain storm optimization algorithm using FPGAs. Microprocessors and microsystems, 74, 103005. https://doi.org/10.1016/j.micpro.2020.103005 DOI: https://doi.org/10.1016/j.micpro.2020.103005
Jin, Q., Xu, Z., & Cai, W. (2021). An improved whale optimization algorithm with random evolution and special reinforcement dual-operation strategy collaboration. Symmetry, 13(2), 238. https://doi.org/10.3390/sym13020238 DOI: https://doi.org/10.3390/sym13020238
Kochol, M. (2023). Linear Algebraic Relations among Cardinalities of Sets of Matroid Functions. Mathematics, 11(11), 2570. https://doi.org/10.3390/math11112570 DOI: https://doi.org/10.3390/math11112570
Kumar, B. A., & Bansal, M. (2023). Face mask detection on photo and real-time video images using Caffe-MobileNetV2 transfer learning. Applied Sciences, 13(2), 935. https://doi.org/10.3390/app13020935 DOI: https://doi.org/10.3390/app13020935
Vayadande, K., Shaikh, R., Narnaware, T., Rothe, S., Bhavar, N., & Deshmukh, S. (2022). Designing Web Crawler Based on Multi-threaded Approach For Authentication of Web Links on Internet. In: 2022 6th International Conference on Electronics, Communication and Aerospace Technology (pp. 1469-1473). IEEE.
https://doi.org/10.1109/ICECA55336.2022.10009614 DOI: https://doi.org/10.1109/ICECA55336.2022.10009614
Ma, X., Wu, S., Pobee, E., Mei, X., Zhang, H., Jiang, B., & Chan, W. K. (2020). Regiontrack: A trace-based sound and complete checker to debug transactional atomicity violations and non-serializable traces. ACM Transactions on Software Engineering and Methodology (TOSEM), 30(1), 1-49. https://doi.org/10.1145/3412377
Ma, X., Wu, S., Pobee, E., Mei, X., Zhang, H., Jiang, B., & Chan, W. K. (2020). Regiontrack: A trace-based sound and complete checker to debug transactional atomicity violations and non-serializable traces. ACM Transactions on Software Engineering and Methodology (TOSEM), 30(1), 1-49. https://doi.org/10.1145/3412377 DOI: https://doi.org/10.1145/3412377
Ma, X., Ashraf, I., & Chan, W. K. (2022). Davida: A Decentralization Approach to Localizing Transaction Sequences for Debugging Transactional Atomicity Violations. IEEE Transactions on Reliability, 72(2), 808-826. https://doi.org/10.1109/TR.2022.3176680 DOI: https://doi.org/10.1109/TR.2022.3176680
Majumdar, S., Chatterjee, N., Das, P. P., & Chakrabarti, A. (2021). A mathematical framework for design discovery from multi-threaded applications using neural sequence solvers. Innovations in Systems and Software Engineering, 17(3), 289-307. https://doi.org/10.1007/s11334-021-00393-8 DOI: https://doi.org/10.1007/s11334-021-00393-8
Moragues, R., Aparicio, J., & Esteve, M. (2023). Ranking the Importance of Variables in a Nonparametric Frontier Analysis Using Unsupervised Machine Learning Techniques. Mathematics, 11(11), 2590. https://doi.org/10.3390/math11112590 DOI: https://doi.org/10.3390/math11112590
Murthy, P. V. R., & Rani, N. (2022). Testing Multi-Threaded Programs by Transformation to Hoare’s CSP. In: 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon) (pp. 1-7). IEEE. https://doi.org/10.1109/QRS54544.2021.00022 DOI: https://doi.org/10.1109/MysuruCon55714.2022.9972724
Muthukrishnan, H., Lustig, D., Villa, O., Wenisch, T., & Nellans, D. (2023). FinePack: Transparently Improving the Efficiency of Fine-Grained Transfers in Multi-GPU Systems. In: 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA) (pp. 516-529). IEEE. https://doi.org/10.1109/HPCA56546.2023.10070949 DOI: https://doi.org/10.1109/HPCA56546.2023.10070949
Pramudita, Y. D., Anamisa, D. R., Putro, S. S., & Rahmawanto, M. A. (2020). Extraction System Web Content Sports New Based On Web Crawler Multi Thread. In: Journal of Physics: Conference Series (Vol. 1569, No. 2, p. 022077). IOP Publishing. https://doi.org/10.1088/1742-6596/1569/2/022077 DOI: https://doi.org/10.1088/1742-6596/1569/2/022077
Rafi, M. E. H., Williams, K., & Qasem, A. (2022). Raptor: Mitigating CPU-GPU False Sharing Under Unified Memory Systems. In: 2022 IEEE 13th International Green and Sustainable Computing Conference (IGSC) (pp. 1-8). IEEE. https://doi.org/10.1109/IGSC55832.2022.9969376. 978-1-6654-6550-2 DOI: https://doi.org/10.1109/IGSC55832.2022.9969376
Siqueira, H., & Kreutz, M. (2018). A simultaneous multithreading processor architecture with predictable timing behavior. In: 2018 VIII Brazilian Symposium on Computing Systems Engineering (SBESC) (pp. 62-66). IEEE. https://doi.org/10.1109/SBESC.2018.00018 DOI: https://doi.org/10.1109/SBESC.2018.00018
Tang, H., Li, C., Zhang, Y., & Luo, Y. (2021). Optimal multilevel media stream caching in cloud-edge environment. The Journal of Supercomputing, 77, 10357-10376. https://doi.org/10.1007/s11227-021-03683-x DOI: https://doi.org/10.1007/s11227-021-03683-x
Vijaykumar, N., Olgun, A., Kanellopoulos, K., Bostanci, F. N., Hassan, H., Lotfi, M., ... & Mutlu, O. (2022). MetaSys: A practical open-source metadata management system to implement and evaluate cross-layer optimizations. ACM Transactions on Architecture and Code Optimization (TACO), 19(2), 1-29. https://doi.org/10.1145/3505250 DOI: https://doi.org/10.1145/3505250
Wu, J., Fan, C., Li, G., Xu, Z., Jin, Z., & Zheng, Y. (2022). A New Heuristic Computation Offloading Method Based on Cache-Assisted Model. Wireless Communications and Mobile Computing, 2022, 3501329. https://doi.org/10.1155/2022/3501329 DOI: https://doi.org/10.1155/2022/3501329
Yang, C., Ashraf, I., Ma, X., Zhang, H., & Chan, W. K. (2021). OPE: Transforming Programs with Clean and Precise Separation of Tested Intraprocedural Program Paths with Path Profiling. In: 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS) (pp. 279-290). IEEE. https://doi.org/10.1109/QRS54544.2021.00039 DOI: https://doi.org/10.1109/QRS54544.2021.00039
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Akhigbe-mudu Thursday Ehis

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors who publish with this journal agree to the following terms:
1) Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License that allows others to share the work with an acknowledgement of the work's authorship and initial publication in this journal.
2) Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgement of its initial publication in this journal.
3) Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work.

